Andrew Buzin
Aug 12, 2024

Hey everyone, I’m Andrew, and I lead AI research at TensorSense. Over the past decade, I’ve been deep in the trenches, building computer vision backends for some of the toughest applications out there: industrial safety, robotics, autonomous vehicles, you name it.
At WWDC 2024, Apple laid out their vision for how LLMs can redefine user experience. TLDR: a lightweight on-device LLM handles the basics, a mid-size model on a private cloud takes care of more complex operations, and when it’s time to get really creative, you bring in a heavy-hitter like GPT-4o.
The most fascinating part of their approach is how they get that tiny on-device LLM to deliver reliable, high-quality results across a wide array of iOS APIs. The secret sauce is in orchestrating adapters—tiny sub-networks that steer LLMs behavior to make it better at a particular task. It's similar to fine-tuning, except you don't have to commit to changing your original model's weights. Seems like Apple stores and uses an adapter for each API / task.
A screenshot from Apple Platforms State of the Union
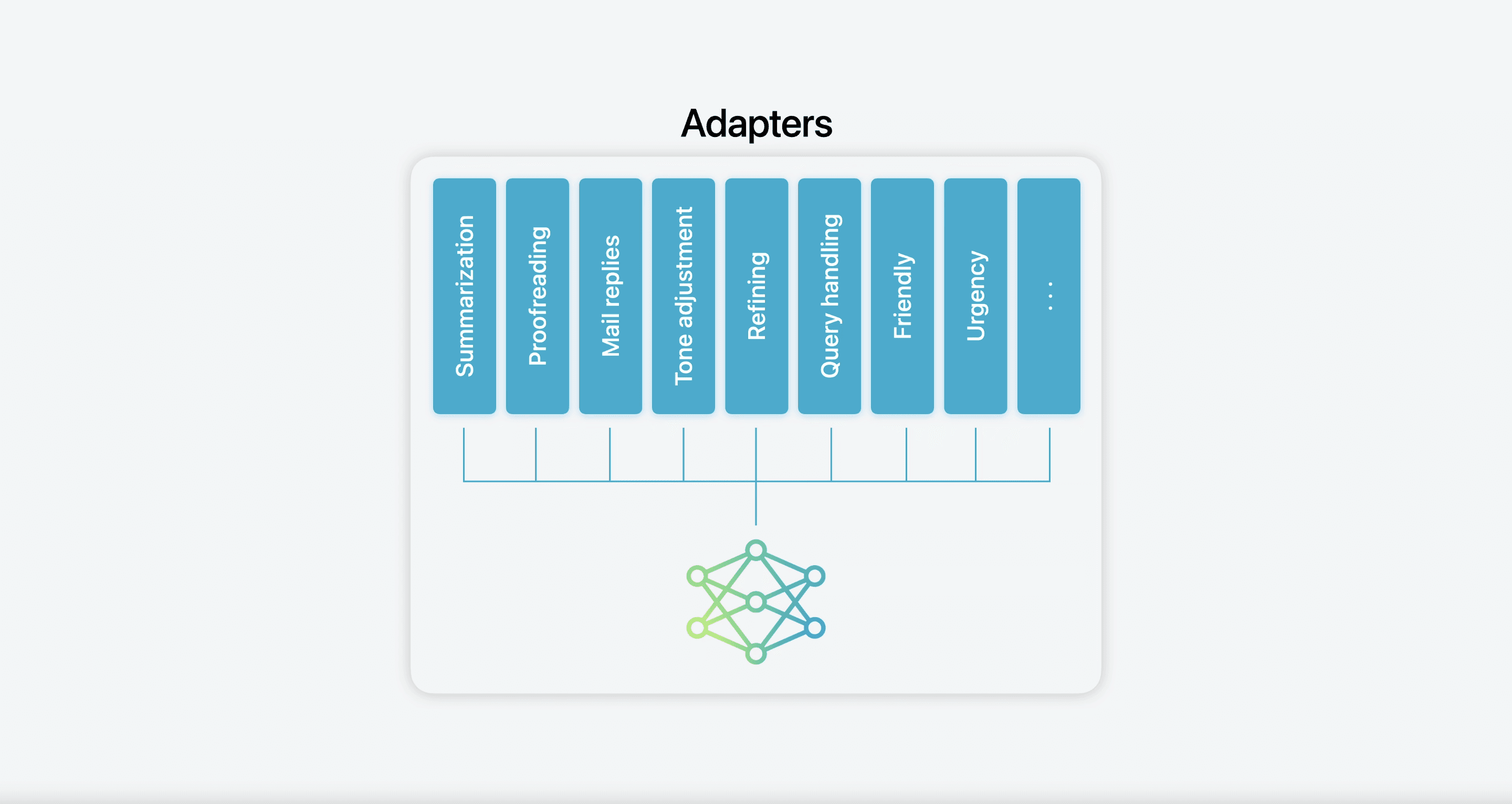
Inspired by Apple’s approach, we at TensorSense wanted to explore the possibility of training and orchestrating a set of adapters for a tiny multimodal LLM to handle computer vision tasks. In this post, I’ll walk you through how to use TensorSense SDK to train multiple adapters for PaliGemma(1)—an open-source 3B multimodal LLM small enough to run on smartphones—and how to deploy a multi-adapter(2) demo.
Sorting trash: two tasks, one model
For this demo, we chose a scenario that’s pretty common for computer vision teams: managing trash through various recycling pipelines. Recycling facilities worldwide rely on computer vision apps for this, making it a great case to demonstrate how different adapters can work together.

Let’s break down the design of this app. The input is a picture with some trash in it, and the output is the same picture with identified objects, along with a JSON file that gives specific directions on what should happen to each object.
We could use instance segmentation to identify and highlight different types of trash. To determine where each item should go, we’d need to consult local waste disposal rules. Finally, we could add details like garbage day schedules or district-specific trash bag requirements. We can handle all this with a single PaliGemma base model by plugging in a task-specific adapter for each step, and imitate RAG for extracting factual data.
One of the reasons why it’s great to approach this task with LLMs is that the traditional way of building such a demo using YOLO and regular expressions often leads to the most painful computer vision problems: poor domain generalization, imbalanced data, and open class classification. Even a small LLM has enough world knowledge to smooth out these issues.
A few words on how multimodal LLMs perform vision segmentations
Fundamentally PaliGemma is a model designed to generate text token by token.
In order to teach it to output segmentation, we need find a way to represent bounding boxes and masks as sequences of tokens. After that, we need to train the model using obscene amounts of data, and then it will hopefully learn how to segment an image.
Luckily, Google's already done the hard part. For PaliGemma, each segmentation mask is represented by a sequence of 20 special tokens. First four of them look like <loc0000> and contain bounding box coordinates. Remaining 16 tokens look like <seg000> and encode the mask as a vector of numbers between 0 and 127. In order to move between this 16-token representation and the original mask we use a special pretrained autoencoder(3). Class labels are included at the end as plain text.

Original segmentation mask for the sample.

Same segmentation mask after being compressed into a text representation.
JSON, of course, is already text, so it hardly needs special treatment. However, following a notebook for Idefics 2(4) I decided to translate JSON labels into an XML-like format. I assume this helps the model to keep track of nested structures by replacing endless curly braces with unique tags.

Example JSON we are using as a target output.

Same structure after the conversion.
The rest of the project is more in line with regular LLM stuff, and is best explained with some hands on examples.
What adapters we are training
I decided to go with a small instance segmentation dataset called TACO(5). It's reasonably clean and looks kind of like what we need.
The first adapter is going to do instance segmentation. Our dataset comes with annotations for 60 different classes, but we are going merge them into a total of 9. We also need to turn masks into text as discussed in the previous section.
The job of the second adapter is to cross-reference segmented items with local waste disposal rules and produce instructions in JSON format. We need to generate some synthetic data for this. Let's pluck label names out of our dataset, combine them with rules(6) and use GPT-4o to generate target JSONs. During training we are going to input segmented images, labels and rules, and ask the model to predict the target part.

Example of an input image for the JSON adapter.
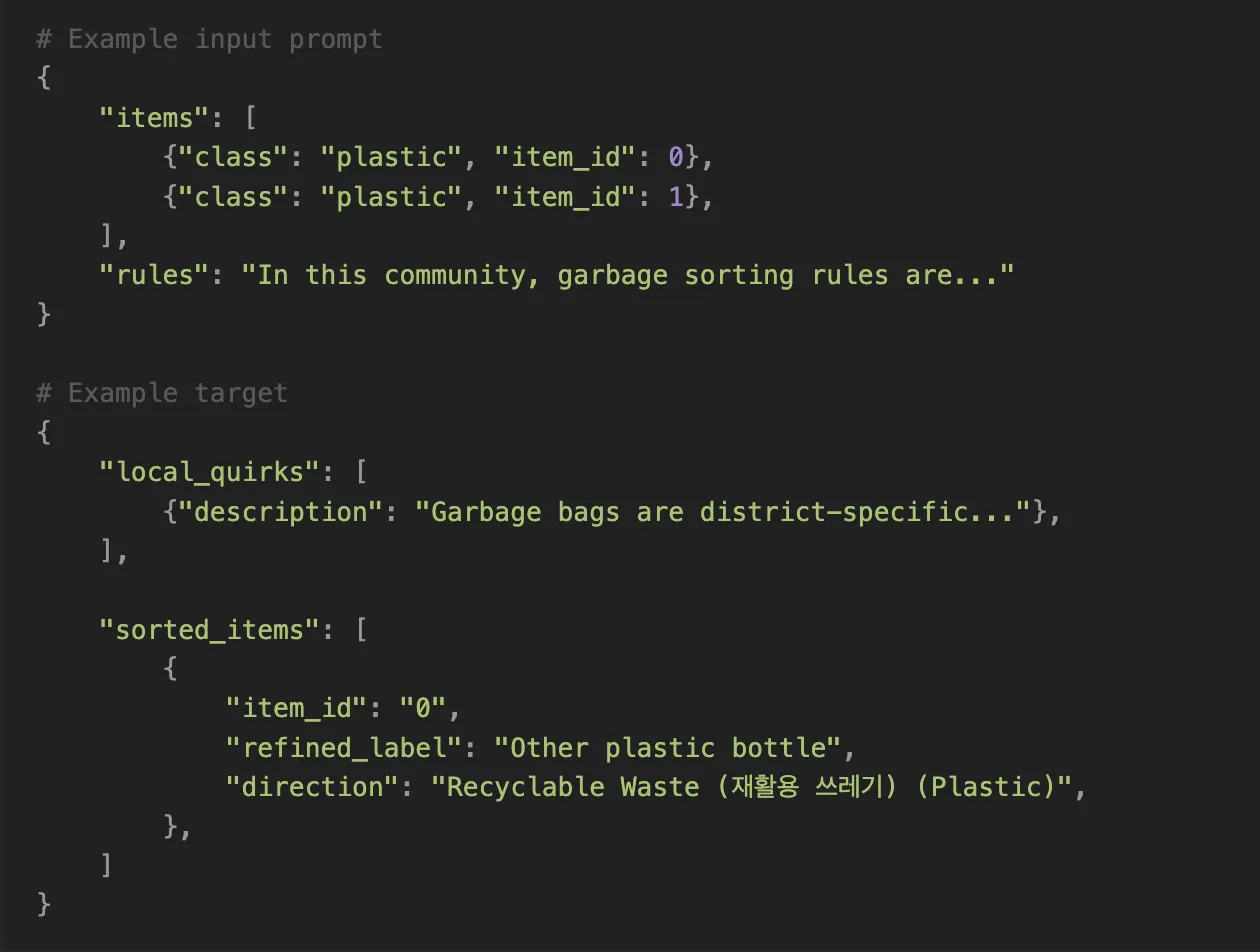
Example text prompt and target for that same adapter.
Training adapters using TensorSense SDK
Implementing all the parts we talked about earlier would surely require some elbow grease.
However, we are going to skip that completely by using the TensorSense Training Toolkit. This is a library we made that comes with tools for the gnarliest parts of the project.
In order to start training, we need to convert both of our datasets into a HuggingFace Datasets(7) format. We will also create a custom collator(8). This is a utility that turns samples into actual LLM input tensors. Luckily, the rest of our workflow is not data-dependent, meaning we can use generic presets from the library. Let's finish the setup by plugging our parts into the factory to get a Trainer for the model.
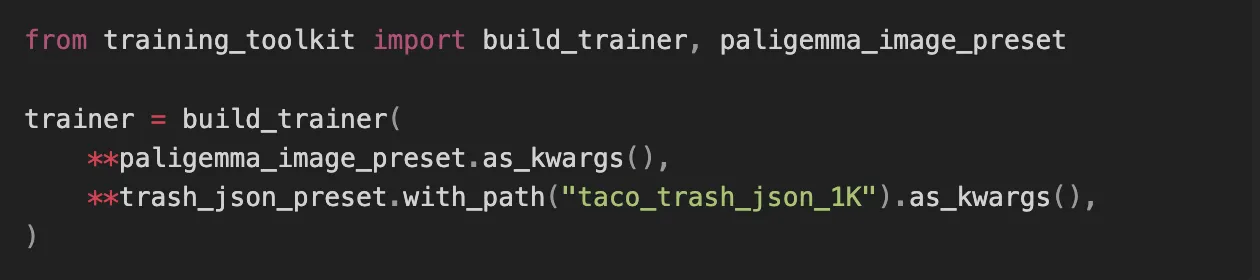
This is basically all we need to do before we can start training the model.
Cooking each of our adapters should take around 20 minutes. Once they are done, we can load both of them together with the base model to get our memory efficient AI system rolling. Now we can call those adapters one after another and get the results.
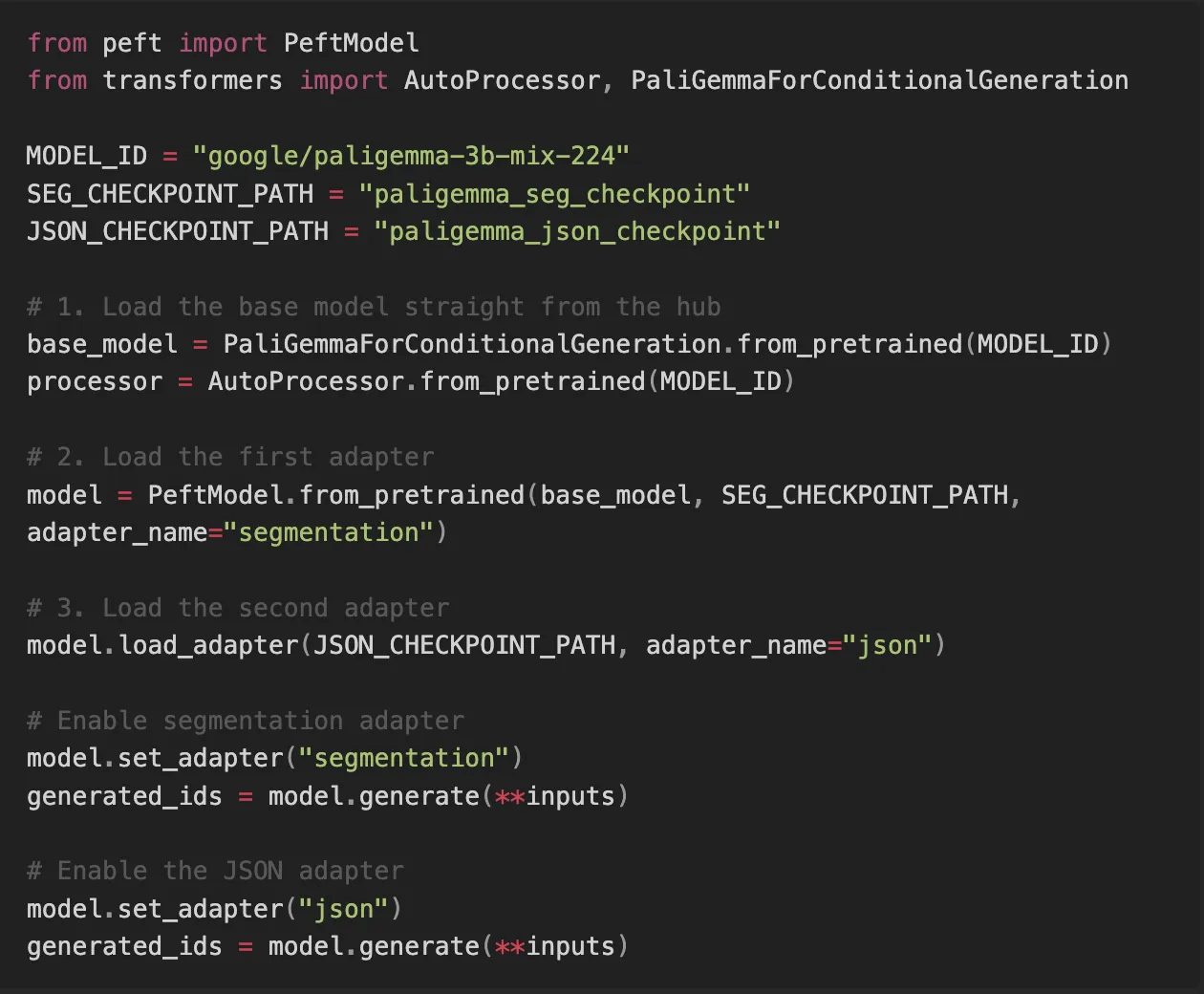
Here’s a notebook that demonstrates training a segmentation adapter, another one that covers training for structured outputs, and a third that shows how to assemble and run the trained adapters.
You can also try out a deployed demo to see how it works. It was trained on ~1,000 samples, so it’s not highly accurate, but with more data, you can easily turn it into a production-ready solution.
Each adapter is under 200MB, and the model itself is 3GB, so you can stack as many adapters as your memory can handle.
As you can see, the training toolkit is a huge time-saver. It comes with presets for PaliGemma for images and VideoLLaVA for videos, as well as data presets for QA, segmentation, and JSON. If you have any feature requests or need more presets, just let us know. Our next updates will focus on making the toolkit even easier for people with zero ML experience.
And don’t forget to star our repo—it really helps us out in more ways than you might think!
