Andrey Buzin
May 3, 2024

We introduce a novel multimodal language model that leverages the strengths of state-space models and transformers to deliver an optimal balance of throughput and accuracy. Inspired by the architecture of LLaVA, we combine VideoMamba video encoder with a lightweight Gemma 2B LLM. This allows the model to reach competitive performance using a fraction of compute and memory of larger models. It is fine-tuned exclusively on openly available datasets, ensuring compliance with data privacy and use standards.
[GitHub] | [Hugging Face] [arXiv (soon)]
Performance in Video QA
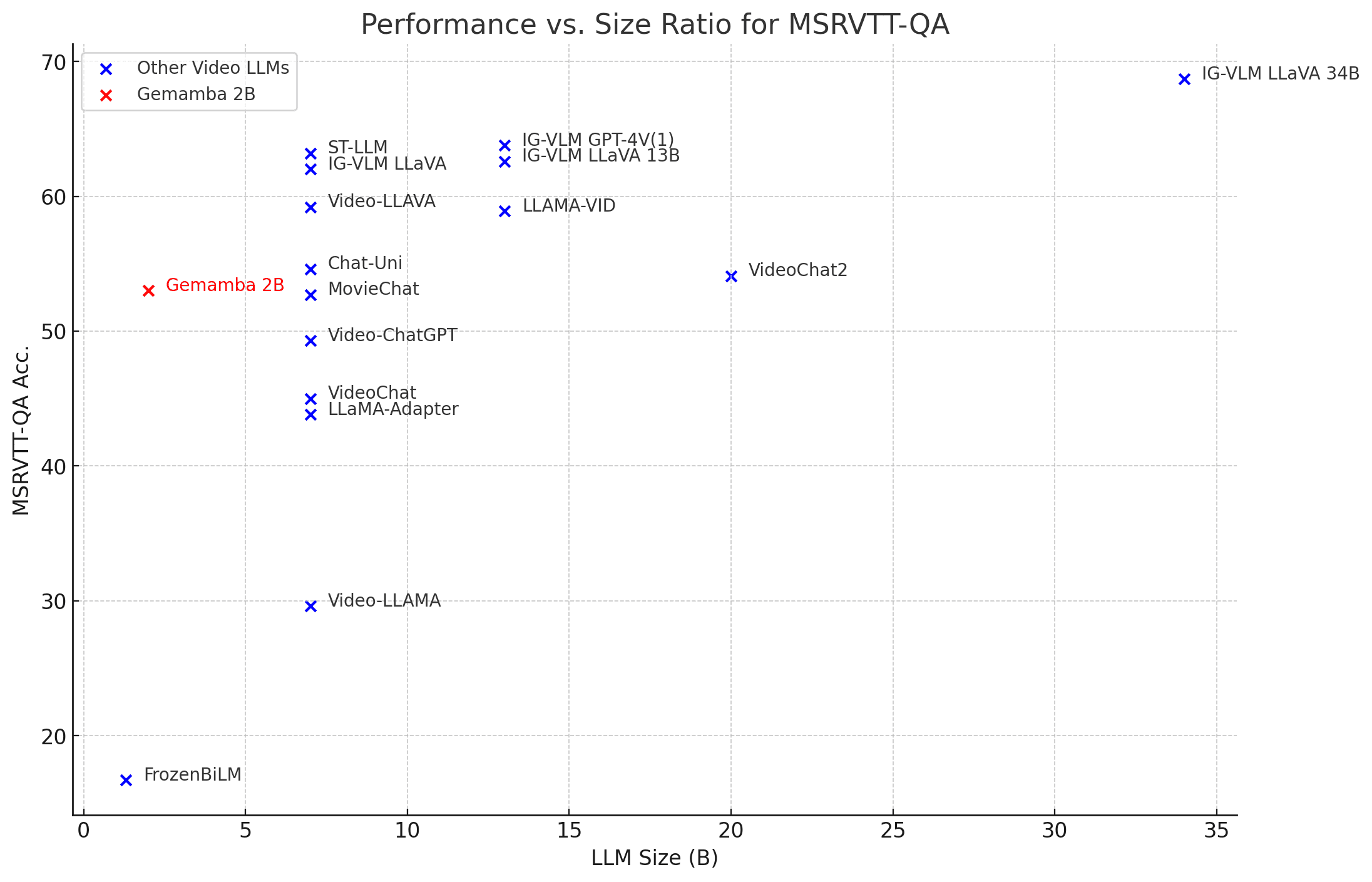
Gemamba 2B v0.7 delivers performance comparable to popular 7B video LLMs, but at 3.5x smaller size:
Why Mamba?
Video is both spatially and temporally sparse in terms of information. At the same time, pieces of information scattered across the video may be globally dependent on each other. This means that a piece of information in a certain region of the frame at a certain time may provide necessary context for a piece in a different region or at a future time.
• Convolutions overcome the redundancy issue by processing video at a local scale first, but they struggle with identifying global dependencies due to their limited receptive field.
• Transformers have a global receptive field, but they are terribly inefficient when scaling to larger inputs. Optimization strategies for attention usually result in a smaller receptive field, thus creating a trade-off.
Mambas combine the efficiency of CNNs, due to them having a state, with the global receptive field of a vanilla Transformer. This makes them a good fit for working with longer sequences that contain global dependencies, such as those found in video reasoning. In fact, the original Mamba has been shown to have 5x the throughput of a similar-sized Transformer, while outperforming it in quality.
Given that no architecture has yet yielded a good solution to this task, we feel comfortable placing our bet on the Mamba architecture to become that solution.
Architecture and training
Since video is a highly redundant medium, this makes it a natural candidate for SSM-based processing. This is why for our video reasoning model we chose to combine a lightweight Gemma 2B LLM with VideoMamba - a Mamba-based video encoder [Li et al., 2024].
We decided to keep the rest of the model as simple as possible, following a classic LLaVA architecture [Liu et al., 2023].

We trained our model using 4xA100 GPUs at batch size 24.
Limitations
It's important to keep in mind that the released model is still in the early stages of training. It hasn't been thoroughly tested and aligned with safety standards. Therefore it is made available for demonstration purposes only not meant to be used in any critical applications.
Getting Started
We release the code for our model on GitHub along with installation and training instructions. Pretrained weights for the model can be found on our HuggingFace 🤗.